Recrutement Google, étape #2
Mardi 28 novembre je me suis rendu dans les locaux de Google à Zürich afin de procéder à la suite du processus de recrutement. L'heure de rendez-vous, fixée à 10h00, n'étant pas trop contraignante, j'ai pris le train à Neyruz à 07h45 pour arriver à 09h38 à Zürich, et finalement 9h45 à Freigutstrasse 12, 8002 Zurich.
Le bâtiment est une ancienne banque privée, de couleur rosé et dont le style s'apparenterait au début du 20ème siècle. La porte d'entrée est fermée à clé, et il faut s'annoncer avant de pouvoir entrer. Puis une fois à l'intérieur, il faut s'inscrire sur un terminal et signer sur une tablette, et un badge autocollant est directement imprimé.
L'intérieur du bâtiment est plutôt blanc, avec du parquet sur le sol, mais ce qui frappe c'est les accessoires (poufs, ballons, coussins) de couleurs vives disposés un peu partout. On se croirait en plein jardin d'enfants. Seul les 2 écrans 20 pouces par place de travail rappellent qu'on est bien dans une entreprise de services.
Ma journée s'est composée de 4 entretiens techniques et d'un repas avec Peter, un des deux ingénieurs qui m'avait interviewé à l'EPFL.
Les questions posées étaient de nouveau très algorithmiques, principalement axées sur l'organisation des données en arbre ou table de hashage, tout en tenant compte de l'ordre de complexité des fonctions proposées.
Un exercice a retenu mon attention et je souhaite vous en faire partager mon expérience :
La donnée est simple : un personne se tient en bas d'un escalier de N marches. A chaque pas, il peut monter une ou deux marches. Combien de possibilités de configuration de trajets différents a-t-il pour monter l'escalier ?
L'illustration ci-dessous schématise le problème.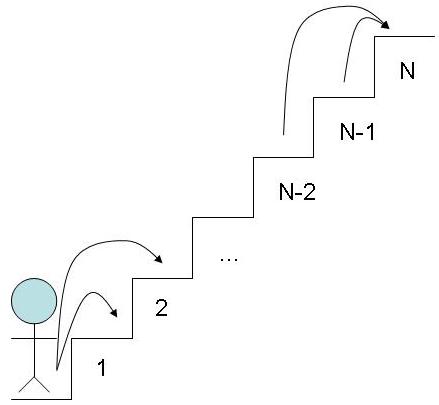
Le raisonnement approprié pour ce problème est de se dire que pour atteindre une marche n, la seule possibilité est d'être passé par la marche n-1 ou n-2, et donc le nombre de chemin pour arriver sur la marche n est la somme des possibilités d'arriver sur les cases n-1 et n-2.
On a donc la formule de récurrence suivante :
Fn = Fn − 1 + Fn − 2
qui devrait nous faire penser à la suite de Fibonacci.
La suite de la question est simplement : comment peut-on calculer de manière efficace une telle suite ?
Il est possible de calculer une suite de Fibonacci de manière itérative, et donc d'une complexité de O(n), mais ce que je ne savais pas c'est qu'il existe une manière encore plus efficace pour calculer en O(log(n)) !
Cette solution repose sur deux propriétés : l'expression matricielle du problème, et le calcul de puissance.
La suite de Fibonacci peut donc s'exprimer sous la forme matricielle suivante : 
Ce qui nous amène à l'expression suivante : 
On voit apparaitre un matrice 2x2 élevée à la puissance n. On peut donc utiliser l'algorithme square-and-multiply (donné ci-dessou) pour la calculée, qui lui est en O(log(n)).
CQFD. Des questions ? Des remarques ?
Je suis reparti vers 15h30, fatigué mais content. Je devrais avoir une réponse dans le courant de la semaine prochaine quant à leur envie de m'engager ou pas.
Suite au prochain (et peut-être dernier) épisode...

